
Redux Style Guide
Introduction
This is the official style guide for writing Redux code. It lists our recommended patterns, best practices, and suggested approaches for writing Redux applications.
Both the Redux core library and most of the Redux documentation are unopinionated. There are many ways to use Redux, and much of the time there is no single "right" way to do things.
However, time and experience have shown that for some topics, certain approaches work better than others. In addition, many developers have asked us to provide official guidance to reduce decision fatigue.
With that in mind, we've put together this list of recommendations to help you avoid errors, bikeshedding, and anti-patterns. We also understand that team preferences vary and different projects have different requirements, so no style guide will fit all sizes. You are encouraged to follow these recommendations, but take the time to evaluate your own situation and decide if they fit your needs.
Finally, we'd like to thank the Vue documentation authors for writing the Vue Style Guide page, which was the inspiration for this page.
Rule Categories
We've divided these rules into three categories:
Priority A: Essential
These rules help prevent errors, so learn and abide by them at all costs. Exceptions may exist, but should be very rare and only be made by those with expert knowledge of both JavaScript and Redux.
Priority B: Strongly Recommended
These rules have been found to improve readability and/or developer experience in most projects. Your code will still run if you violate them, but violations should be rare and well-justified. Follow these rules whenever it is reasonably possible.
Priority C: Recommended
Where multiple, equally good options exist, an arbitrary choice can be made to ensure consistency. In these rules, we describe each acceptable option and suggest a default choice. That means you can feel free to make a different choice in your own codebase, as long as you're consistent and have a good reason. Please do have a good reason though!
Priority A Rules: Essential
Do Not Mutate State
Mutating state is the most common cause of bugs in Redux applications, including components failing to re-render properly, and will also break time-travel debugging in the Redux DevTools. Actual mutation of state values should always be avoided, both inside reducers and in all other application code.
Use tools such as redux-immutable-state-invariant to catch mutations during development, and Immer to avoid accidental mutations in state updates.
Note: it is okay to modify copies of existing values - that is a normal part of writing immutable update logic. Also, if you are using the Immer library for immutable updates, writing "mutating" logic is acceptable because the real data isn't being mutated - Immer safely tracks changes and generates immutably-updated values internally.
Reducers Must Not Have Side Effects
Reducer functions should only depend on their state and action arguments, and should only calculate and return a new state value based on those arguments. They must not execute any kind of asynchronous logic (AJAX calls, timeouts, promises), generate random values (Date.now(), Math.random()), modify variables outside the reducer, or run other code that affects things outside the scope of the reducer function.
Note: It is acceptable to have a reducer call other functions that are defined outside of itself, such as imports from libraries or utility functions, as long as they follow the same rules.
Detailed Explanation
The purpose of this rule is to guarantee that reducers will behave predictably when called. For example, if you are doing time-travel debugging, reducer functions may be called many times with earlier actions to produce the "current" state value. If a reducer has side effects, this would cause those effects to be executed during the debugging process, and result in the application behaving in unexpected ways.
There are some gray areas to this rule. Strictly speaking, code such as console.log(state) is a side effect, but in practice has no effect on how the application behaves.
Do Not Put Non-Serializable Values in State or Actions
Avoid putting non-serializable values such as Promises, Symbols, Maps/Sets, functions, or class instances into the Redux store state or dispatched actions. This ensures that capabilities such as debugging via the Redux DevTools will work as expected. It also ensures that the UI will update as expected.
Exception: you may put non-serializable values in actions if the action will be intercepted and stopped by a middleware before it reaches the reducers. Middleware such as
redux-thunkandredux-promiseare examples of this.
Only One Redux Store Per App
A standard Redux application should only have a single Redux store instance, which will be used by the whole application. It should typically be defined in a separate file such as store.js.
Ideally, no app logic will import the store directly. It should be passed to a React component tree via <Provider>, or referenced indirectly via middleware such as thunks. In rare cases, you may need to import it into other logic files, but this should be a last resort.
Priority B Rules: Strongly Recommended
Use Redux Toolkit for Writing Redux Logic
Redux Toolkit is our recommended toolset for using Redux. It has functions that build in our suggested best practices, including setting up the store to catch mutations and enable the Redux DevTools Extension, simplifying immutable update logic with Immer, and more.
You are not required to use RTK with Redux, and you are free to use other approaches if desired, but using RTK will simplify your logic and ensure that your application is set up with good defaults.
Use Immer for Writing Immutable Updates
Writing immutable update logic by hand is frequently difficult and prone to errors. Immer allows you to write simpler immutable updates using "mutative" logic, and even freezes your state in development to catch mutations elsewhere in the app. We recommend using Immer for writing immutable update logic, preferably as part of Redux Toolkit.
Structure Files as Feature Folders with Single-File Logic
Redux itself does not care about how your application's folders and files are structured. However, co-locating logic for a given feature in one place typically makes it easier to maintain that code.
Because of this, we recommend that most applications should structure files using a "feature folder" approach (all files for a feature in the same folder). Within a given feature folder, the Redux logic for that feature should be written as a single "slice" file, preferably using the Redux Toolkit createSlice API. (This is also known as the "ducks" pattern). While older Redux codebases often used a "folder-by-type" approach with separate folders for "actions" and "reducers", keeping related logic together makes it easier to find and update that code.
It is important to know that "slice" is a concept in redux-toolkit. It does the same thing as the "ducks" pattern but in a more "automatic" way. Slice v.s Ducks is like create-react-app v.s. React project by hand.
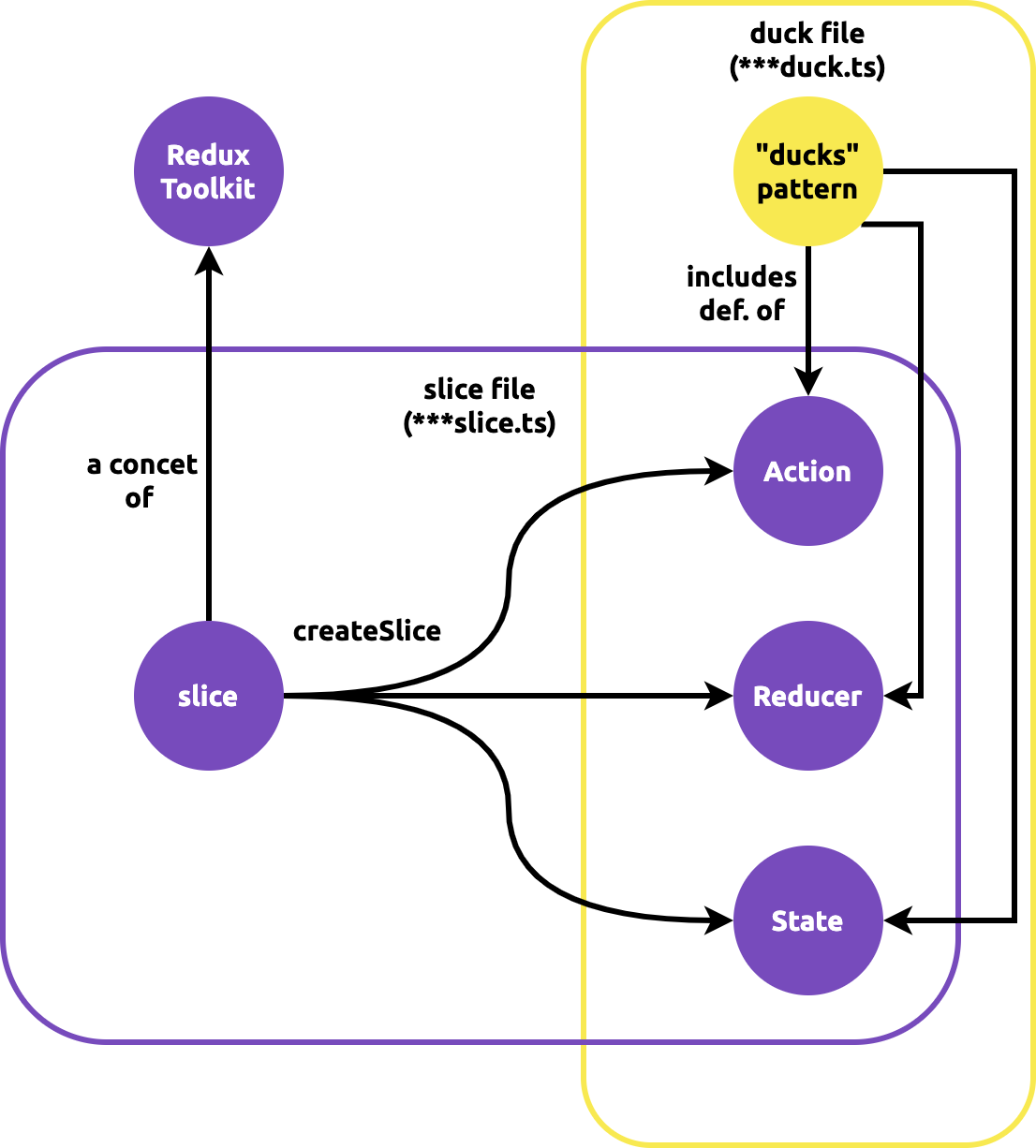
Detailed Explanation: Example Folder Structure
An example folder structure might look something like:
/srcindex.tsx: Entry point file that renders the React component tree/appstore.ts: store setuprootReducer.ts: root reducer (optional)App.tsx: root React component
/common: hooks, generic components, utils, etc/features: contains all "feature folders"/todos: a single feature foldertodosSlice.ts: Redux reducer logic and associated actionsTodos.tsx: a React component
/app contains app-wide setup and layout that depends on all the other folders.
/common contains truly generic and reusable utilities and components.
/features has folders that contain all functionality related to a specific feature. In this example, todosSlice.ts is a "duck"-style file that contains a call to RTK's createSlice() function, and exports the slice reducer and action creators.
Put as Much Logic as Possible in Reducers
Wherever possible, try to put as much of the logic for calculating a new state into the appropriate reducer, rather than in the code that prepares and dispatches the action (like a click handler). This helps ensure that more of the actual app logic is easily testable, enables more effective use of time-travel debugging, and helps avoid common mistakes that can lead to mutations and bugs.
There are valid cases where some or all of the new state should be calculated first (such as generating a unique ID), but that should be kept to a minimum.
Detailed Explanation
The Redux core does not actually care whether a new state value is calculated in the reducer or in the action creation logic. For example, for a todo app, the logic for a "toggle todo" action requires immutably updating an array of todos. It is legal to have the action contain just the todo ID and calculate the new array in the reducer:
// Click handler:
const onTodoClicked = (id) => {
dispatch({type: "todos/toggleTodo", payload: {id}})
}
// Reducer:
case "todos/toggleTodo": {
return state.map(todo => {
if(todo.id !== action.payload.id) return todo;
return {...todo, completed: !todo.completed };
})
}
And also to calculate the new array first and put the entire new array in the action:
// Click handler:
const onTodoClicked = id => {
const newTodos = todos.map(todo => {
if (todo.id !== id) return todo
return { ...todo, completed: !todo.completed }
})
dispatch({ type: 'todos/toggleTodo', payload: { todos: newTodos } })
}
// Reducer:
case "todos/toggleTodo":
return action.payload.todos;
However, doing the logic in the reducer is preferable for several reasons:
- Reducers are always easy to test, because they are pure functions - you just call
const result = reducer(testState, action), and assert that the result is what you expected. So, the more logic you can put in a reducer, the more logic you have that is easily testable. - Redux state updates must always follow the rules of immutable updates. Most Redux users realize they have to follow the rules inside a reducer, but it's not obvious that you also have to do this if the new state is calculated outside the reducer. This can easily lead to mistakes like accidental mutations, or even reading a value from the Redux store and passing it right back inside an action. Doing all of the state calculations in a reducer avoids those mistakes.
- If you are using Redux Toolkit or Immer, it is much easier to write immutable update logic in reducers, and Immer will freeze the state and catch accidental mutations.
- Time-travel debugging works by letting you "undo" a dispatched action, then either do something different or "redo" the action. In addition, hot-reloading of reducers normally involves re-running the new reducer with the existing actions. If you have a correct action but a buggy reducer, you can edit the reducer to fix the bug, hot-reload it, and you should get the correct state right away. If the action itself was wrong, you'd have to re-run the steps that led to that action being dispatched. So, it's easier to debug if more logic is in the reducer.
- Finally, putting logic in reducers means you know where to look for the update logic, instead of having it scattered in random other parts of the application code.
Reducers Should Own the State Shape
The Redux root state is owned and calculated by the single root reducer function. For maintainability, that reducer is intended to be split up by key/value "slices", with each "slice reducer" being responsible for providing an initial value and calculating the updates to that slice of the state.
In addition, slice reducers should exercise control over what other values are returned as part of the calculated state. Minimize the use of "blind spreads/returns" like return action.payload or return {...state, ...action.payload}, because those rely on the code that dispatched the action to correctly format the contents, and the reducer effectively gives up its ownership of what that state looks like. That can lead to bugs if the action contents are not correct.
Note: A "spread return" reducer may be a reasonable choice for scenarios like editing data in a form, where writing a separate action type for each individual field would be time-consuming and of little benefit.
Detailed Explanation
Picture a "current user" reducer that looks like:
const initialState = {
firstName: null,
lastName: null,
age: null,
};
export default usersReducer = (state = initialState, action) {
switch(action.type) {
case "users/userLoggedIn": {
return action.payload;
}
default: return state;
}
}
In this example, the reducer completely assumes that action.payload is going to be a correctly formatted object.
However, imagine if some part of the code were to dispatch a "todo" object inside the action, instead of a "user" object:
dispatch({
type: 'users/userLoggedIn',
payload: {
id: 42,
text: 'Buy milk'
}
})
The reducer would blindly return the todo, and now the rest of the app would likely break when it tries to read the user from the store.
This could be at least partly fixed if the reducer has some validation checks to ensure that action.payload actually has the right fields, or tries to read the right fields out by name. That does add more code, though, so it's a question of trading off more code for safety.
Use of static typing does make this kind of code safer and somewhat more acceptable. If the reducer knows that action is a PayloadAction<User>, then it should be safe to do return action.payload.
Name State Slices Based On the Stored Data
As mentioned in Reducers Should Own the State Shape, the standard approach for splitting reducer logic is based on "slices" of state. Correspondingly, combineReducers is the standard function for joining those slice reducers into a larger reducer function.
The key names in the object passed to combineReducers will define the names of the keys in the resulting state object. Be sure to name these keys after the data that is kept inside, and avoid use of the word "reducer" in the key names. Your object should look like {users: {}, posts: {}}, rather than {usersReducer: {}, postsReducer: {}}.
Detailed Explanation
Object literal shorthand makes it easy to define a key name and a value in an object at the same time:
const data = 42
const obj = { data }
// same as: {data: data}
combineReducers accepts an object full of reducer functions, and uses that to generate state objects that have the same key names. This means that the key names in the functions object define the key names in the state object.
This results in a common mistake, where a reducer is imported using "reducer" in the variable name, and then passed to combineReducers using the object literal shorthand:
import usersReducer from 'features/users/usersSlice'
const rootReducer = combineReducers({
usersReducer
})
In this case, use of the object literal shorthand created an object like {usersReducer: usersReducer}. So, "reducer" is now in the state key name. This is redundant and useless.
Instead, define key names that only relate to the data inside. We suggest using explicit key: value syntax for clarity:
import usersReducer from 'features/users/usersSlice'
import postsReducer from 'features/posts/postsSlice'
const rootReducer = combineReducers({
users: usersReducer,
posts: postsReducer
})
It's a bit more typing, but it results in the most understandable code and state definition.
Organize State Structure Based on Data Types, Not Components
Root state slices should be defined and named based on the major data types or areas of functionality in your application, not based on which specific components you have in your UI. This is because there is not a strict 1:1 correlation between data in the Redux store and components in the UI, and many components may need to access the same data. Think of the state tree as a sort of global database that any part of the app can access to read just the pieces of state needed in that component.
For example, a blogging app might need to track who is logged in, information on authors and posts, and perhaps some info on what screen is active. A good state structure might look like {auth, posts, users, ui}. A bad structure would be something like {loginScreen, usersList, postsList}.
Treat Reducers as State Machines
Many Redux reducers are written "unconditionally". They only look at the dispatched action and calculate a new state value, without basing any of the logic on what the current state might be. This can cause bugs, as some actions may not be "valid" conceptually at certain times depending on the rest of the app logic. For example, a "request succeeded" action should only have a new value calculated if the state says that it's already "loading", or an "update this item" action should only be dispatched if there is an item marked as "being edited".
To fix this, treat reducers as "state machines", where the combination of both the current state and the dispatched action determines whether a new state value is actually calculated, not just the action itself unconditionally.
Detailed Explanation
A finite state machine is a useful way of modeling something that should only be in one of a finite number of "finite states" at any time. For example, if you have a fetchUserReducer, the finite states can be:
"idle"(fetching not started yet)"loading"(currently fetching the user)"success"(user fetched successfully)"failure"(user failed to fetch)
To make these finite states clear and make impossible states impossible, you can specify a property that holds this finite state:
const initialUserState = {
status: 'idle', // explicit finite state
user: null,
error: null
}
With TypeScript, this also makes it easy to use discriminated unions to represent each finite state. For instance, if state.status === 'success', then you would expect state.user to be defined and wouldn't expect state.error to be truthy. You can enforce this with types.
Typically, reducer logic is written by taking the action into account first. When modeling logic with state machines, it's important to take the state into account first. Creating "finite state reducers" for each state helps encapsulate behavior per state:
import {
FETCH_USER,
// ...
} from './actions'
const IDLE_STATUS = 'idle';
const LOADING_STATUS = 'loading';
const SUCCESS_STATUS = 'success';
const FAILURE_STATUS = 'failure';
const fetchIdleUserReducer = (state, action) => {
// state.status is "idle"
switch (action.type) {
case FETCH_USER:
return {
...state,
status: LOADING_STATUS
}
}
default:
return state;
}
}
// ... other reducers
const fetchUserReducer = (state, action) => {
switch (state.status) {
case IDLE_STATUS:
return fetchIdleUserReducer(state, action);
case LOADING_STATUS:
return fetchLoadingUserReducer(state, action);
case SUCCESS_STATUS:
return fetchSuccessUserReducer(state, action);
case FAILURE_STATUS:
return fetchFailureUserReducer(state, action);
default:
// this should never be reached
return state;
}
}
Now, since you're defining behavior per state instead of per action, you also prevent impossible transitions. For instance, a FETCH_USER action should have no effect when status === LOADING_STATUS, and you can enforce that, instead of accidentally introducing edge-cases.
Normalize Complex Nested/Relational State
Many applications need to cache complex data in the store. That data is often received in a nested form from an API, or has relations between different entities in the data (such as a blog that contains Users, Posts, and Comments).
Prefer storing that data in a "normalized" form in the store. This makes it easier to look up items based on their ID and update a single item in the store, and ultimately leads to better performance patterns.
Keep State Minimal and Derive Additional Values
Whenever possible, keep the actual data in the Redux store as minimal as possible, and derive additional values from that state as needed. This includes things like calculating filtered lists or summing up values. As an example, a todo app would keep an original list of todo objects in state, but derive a filtered list of todos outside the state whenever the state is updated. Similarly, a check for whether all todos have been completed, or number of todos remaining, can be calculated outside the store as well.
This has several benefits:
- The actual state is easier to read
- Less logic is needed to calculate those additional values and keep them in sync with the rest of the data
- The original state is still there as a reference and isn't being replaced
Deriving data is often done in "selector" functions, which can encapsulate the logic for doing the derived data calculations. In order to improve performance, these selectors can be memoized to cache previous results, using libraries like reselect and proxy-memoize.
Model Actions as Events, Not Setters
Redux does not care what the contents of the action.type field are - it just has to be defined. It is legal to write action types in present tense ("users/update"), past tense ("users/updated"), described as an event ("upload/progress"), or treated as a "setter" ("users/setUserName"). It is up to you to determine what a given action means in your application, and how you model those actions.
However, we recommend trying to treat actions more as "describing events that occurred", rather than "setters". Treating actions as "events" generally leads to more meaningful action names, fewer total actions being dispatched, and a more meaningful action log history. Writing "setters" often results in too many individual action types, too many dispatches, and an action log that is less meaningful.
Detailed Explanation
Imagine you've got a restaurant app, and someone orders a pizza and a bottle of Coke. You could dispatch an action like:
{ type: "food/orderAdded", payload: {pizza: 1, coke: 1} }
Or you could dispatch:
{
type: "orders/setPizzasOrdered",
payload: {
amount: getState().orders.pizza + 1,
}
}
{
type: "orders/setCokesOrdered",
payload: {
amount: getState().orders.coke + 1,
}
}
The first example would be an "event". "Hey, someone ordered a pizza and a pop, deal with it somehow".
The second example is a "setter". "I know there are fields for 'pizzas ordered' and 'pops ordered', and I am commanding you to set their current values to these numbers".
The "event" approach only really needed a single action to be dispatched, and it's more flexible. It doesn't matter how many pizzas were already ordered. Maybe there's no cooks available, so the order gets ignored.
With the "setter" approach, the client code needed to know more about what the actual structure of the state is, what the "right" values should be, and ended up actually having to dispatch multiple actions to finish the "transaction".
Write Meaningful Action Names
The action.type field serves two main purposes:
- Reducer logic checks the action type to see if this action should be handled to calculate a new state
- Action types are shown in the Redux DevTools history log for you to read
Per Model Actions as "Events", the actual contents of the type field do not matter to Redux itself. However, the type value does matter to you, the developer. Actions should be written with meaningful, informative, descriptive type fields. Ideally, you should be able to read through a list of dispatched action types, and have a good understanding of what happened in the application without even looking at the contents of each action. Avoid using very generic action names like "SET_DATA" or "UPDATE_STORE", as they don't provide meaningful information on what happened.
Allow Many Reducers to Respond to the Same Action
Redux reducer logic is intended to be split into many smaller reducers, each independently updating their own portion of the state tree, and all composed back together to form the root reducer function. When a given action is dispatched, it might be handled by all, some, or none of the reducers.
As part of this, you are encouraged to have many reducer functions all handle the same action separately if possible. In practice, experience has shown that most actions are typically only handled by a single reducer function, which is fine. But, modeling actions as "events" and allowing many reducers to respond to those actions will typically allow your application's codebase to scale better, and minimize the number of times you need to dispatch multiple actions to accomplish one meaningful update.
Avoid Dispatching Many Actions Sequentially
Avoid dispatching many actions in a row to accomplish a larger conceptual "transaction". This is legal, but will usually result in multiple relatively expensive UI updates, and some of the intermediate states could be potentially invalid by other parts of the application logic. Prefer dispatching a single "event"-type action that results in all of the appropriate state updates at once, or consider use of action batching addons to dispatch multiple actions with only a single UI update at the end.
Detailed Explanation
There is no limit on how many actions you can dispatch in a row. However, each dispatched action does result in execution of all store subscription callbacks (typically one or more per Redux-connected UI component), and will usually result in UI updates.
While UI updates queued from React event handlers will usually be batched into a single React render pass, updates queued outside of those event handlers are not. This includes dispatches from most async functions, timeout callbacks, and non-React code. In those situations, each dispatch will result in a complete synchronous React render pass before the dispatch is done, which will decrease performance.
In addition, multiple dispatches that are conceptually part of a larger "transaction"-style update sequence will result in intermediate states that might not be considered valid. For example, if actions "UPDATE_A", "UPDATE_B", and "UPDATE_C" are dispatched in a row, and some code is expecting all three of a, b, and c to be updated together, the state after the first two dispatches will effectively be incomplete because only one or two of them has been updated.
If multiple dispatches are truly necessary, consider batching the updates in some way. Depending on your use case, this may just be batching React's own renders (possibly using batch() from React-Redux), debouncing the store notification callbacks, or grouping many actions into a larger single dispatch that only results in one subscriber notification. See the FAQ entry on "reducing store update events" for additional examples and links to related addons.
Evaluate Where Each Piece of State Should Live
The "Three Principles of Redux" says that "the state of your whole application is stored in a single tree". This phrasing has been over-interpreted. It does not mean that literally every value in the entire app must be kept in the Redux store. Instead, there should be a single place to find all values that you consider to be global and app-wide. Values that are "local" should generally be kept in the nearest UI component instead.
Because of this, it is up to you as a developer to decide what state should actually live in the Redux store, and what should stay in component state. Use these rules of thumb to help evaluate each piece of state and decide where it should live.
Use the React-Redux Hooks API
Prefer using the React-Redux hooks API (useSelector and useDispatch) as the default way to interact with a Redux store from your React components. While the classic connect API still works fine and will continue to be supported, the hooks API is generally easier to use in several ways. The hooks have less indirection, less code to write, and are simpler to use with TypeScript than connect is.
The hooks API does introduce some different tradeoffs than connect does in terms of performance and data flow, but we now recommend them as the default.
Detailed Explanation
The classic connect API is a Higher Order Component. It generates a new wrapper component that subscribes to the store, renders your own component, and passes down data from the store and action creators as props.
This is a deliberate level of indirection, and allows you to write "presentational"-style components that receive all their values as props, without being specifically dependent on Redux.
The introduction of hooks has changed how most React developers write their components. While the "container/presentational" concept is still valid, hooks push you to write components that are responsible for requesting their own data internally by calling an appropriate hook. This leads to different approaches in how we write and test components and logic.
The indirection of connect has always made it a bit difficult for some users to follow the data flow. In addition, connect's complexity has made it very difficult to type correctly with TypeScript, due to the multiple overloads, optional parameters, merging of props from mapState / mapDispatch / parent component, and binding of action creators and thunks.
useSelector and useDispatch eliminate the indirection, so it's much more clear how your own component is interacting with Redux. Since useSelector just accepts a single selector, it's much easier to define with TypeScript, and the same goes for useDispatch.
For more details, see Redux maintainer Mark Erikson's post and conference talk on the tradeoffs between hooks and HOCs:
- Thoughts on React Hooks, Redux, and Separation of Concerns
- ReactBoston 2019: Hooks, HOCs, and Tradeoffs
Also see the React-Redux hooks API docs for info on how to correctly optimize components and handle rare edge cases.
Connect More Components to Read Data from the Store
Prefer having more UI components subscribed to the Redux store and reading data at a more granular level. This typically leads to better UI performance, as fewer components will need to render when a given piece of state changes.
For example, rather than just connecting a <UserList> component and reading the entire array of users, have <UserList> retrieve a list of all user IDs, render list items as <UserListItem userId={userId}>, and have <UserListItem> be connected and extract its own user entry from the store.
This applies for both the React-Redux connect() API and the useSelector() hook.
Use the Object Shorthand Form of mapDispatch with connect
The mapDispatch argument to connect can be defined as either a function that receives dispatch as an argument, or an object containing action creators. We recommend always using the "object shorthand" form of mapDispatch, as it simplifies the code considerably. There is almost never a real need to write mapDispatch as a function.
Call useSelector Multiple Times in Function Components
When retrieving data using the useSelector hook, prefer calling useSelector many times and retrieving smaller amounts of data, instead of having a single larger useSelector call that returns multiple results in an object. Unlike mapState, useSelector is not required to return an object, and having selectors read smaller values means it is less likely that a given state change will cause this component to render.
However, try to find an appropriate balance of granularity. If a single component does need all fields in a slice of the state , just write one useSelector that returns that whole slice instead of separate selectors for each individual field.
Use Static Typing
Use a static type system like TypeScript or Flow rather than plain JavaScript. The type systems will catch many common mistakes, improve the documentation of your code, and ultimately lead to better long-term maintainability. While Redux and React-Redux were originally designed with plain JS in mind, both work well with TS and Flow. Redux Toolkit is specifically written in TS and is designed to provide good type safety with a minimal amount of additional type declarations.
Use the Redux DevTools Extension for Debugging
Configure your Redux store to enable debugging with the Redux DevTools Extension. It allows you to view:
- The history log of dispatched actions
- The contents of each action
- The final state after an action was dispatched
- The diff in the state after an action
- The function stack trace showing the code where the action was actually dispatched
In addition, the DevTools allows you to do "time-travel debugging", stepping back and forth in the action history to see the entire app state and UI at different points in time.
Redux was specifically designed to enable this kind of debugging, and the DevTools are one of the most powerful reasons to use Redux.
Use Plain JavaScript Objects for State
Prefer using plain JavaScript objects and arrays for your state tree, rather than specialized libraries like Immutable.js. While there are some potential benefits to using Immutable.js, most of the commonly stated goals such as easy reference comparisons are a property of immutable updates in general, and do not require a specific library. This also keeps bundle sizes smaller and reduces complexity from data type conversions.
As mentioned above, we specifically recommend using Immer if you want to simplify immutable update logic, specifically as part of Redux Toolkit.
Detailed Explanation
Immutable.js has been semi-frequently used in Redux apps since the beginning. There are several common reasons stated for using Immutable.js:
- Performance improvements from cheap reference comparisons
- Performance improvements from making updates thanks to specialized data structures
- Prevention of accidental mutations
- Easier nested updates via APIs like
setIn()
There are some valid aspects to those reasons, but in practice, the benefits aren't as good as stated, and there's multiple negatives to using it:
- Cheap reference comparisons are a property of any immutable updates, not just Immutable.js
- Accidental mutations can be prevented via other mechanisms, such as using Immer (which eliminates accident-prone manual copying logic, and deep-freezes state in development by default) or
redux-immutable-state-invariant(which checks state for mutations) - Immer allows simpler update logic overall, eliminating the need for
setIn() - Immutable.js has a very large bundle size
- The API is fairly complex
- The API "infects" your application's code. All logic must know whether it's dealing with plain JS objects or Immutable objects
- Converting from Immutable objects to plain JS objects is relatively expensive, and always produces completely new deep object references
- Lack of ongoing maintenance to the library
The strongest remaining reason to use Immutable.js is fast updates of very large objects (tens of thousands of keys). Most applications won't deal with objects that large.
Overall, Immutable.js adds too much overhead for too little practical benefit. Immer is a much better option.
Priority C Rules: Recommended
Write Action Types as domain/eventName
The original Redux docs and examples generally used a "SCREAMING_SNAKE_CASE" convention for defining action types, such as "ADD_TODO" and "INCREMENT". This matches typical conventions in most programming languages for declaring constant values. The downside is that the uppercase strings can be hard to read.
Other communities have adopted other conventions, usually with some indication of the "feature" or "domain" the action is related to, and the specific action type. The NgRx community typically uses a pattern like "[Domain] Action Type", such as "[Login Page] Login". Other patterns like "domain:action" have been used as well.
Redux Toolkit's createSlice function currently generates action types that look like "domain/action", such as "todos/addTodo". Going forward, we suggest using the "domain/action" convention for readability.
Write Actions Using the Flux Standard Action Convention
The original "Flux Architecture" documentation only specified that action objects should have a type field, and did not give any further guidance on what kinds of fields or naming conventions should be used for fields in actions. To provide consistency, Andrew Clark created a convention called "Flux Standard Actions" early in Redux's development. Summarized, the FSA convention says that actions:
- Should always put their data into a
payloadfield - May have a
metafield for additional info - May have an
errorfield to indicate the action represents a failure of some kind
Many libraries in the Redux ecosystem have adopted the FSA convention, and Redux Toolkit generates action creators that match the FSA format.
Prefer using FSA-formatted actions for consistency.
Note: The FSA spec says that "error" actions should set
error: true, and use the same action type as the "valid" form of the action. In practice, most developers write separate action types for the "success" and "error" cases. Either is acceptable.
Use Action Creators
"Action creator" functions started with the original "Flux Architecture" approach. With Redux, action creators are not strictly required. Components and other logic can always call dispatch({type: "some/action"}) with the action object written inline.
However, using action creators provides consistency, especially in cases where some kind of preparation or additional logic is needed to fill in the contents of the action (such as generating a unique ID).
Prefer using action creators for dispatching any actions. However, rather than writing action creators by hand, we recommend using the createSlice function from Redux Toolkit, which will generate action creators and action types automatically.
Use RTK Query for Data Fetching
In practice, the single most common use case for side effects in a typical Redux app is fetching and caching data from the server.
Because of this, we recommend using RTK Query as the default approach for data fetching and caching in a Redux app. RTK Query has been designed to correctly manage the logic for fetching data from the server as needed, caching it, deduplicating requests, updating components, and much more. We recommend against writing data fetching logic by hand in almost all cases.
Use Thunks and Listeners for Other Async Logic
Redux was designed to be extensible, and the middleware API was specifically created to allow different forms of async logic to be plugged into the Redux store. That way, users wouldn't be forced to learn a specific library like RxJS if it wasn't appropriate for their needs.
This led to a wide variety of Redux async middleware addons being created, and that in turn has caused confusion and questions over which async middleware should be used.
We recommend using the Redux thunk middleware for imperative logic, such as complex sync logic that needs access to dispatch or getState, and moderately complex async logic. This includes use cases like moving logic out of components.
We recommend using the RTK "listener" middleware" for "reactive" logic that needs to respond to dispatched actions or state changes, such as longer-running async workflows and "background thread"-type behavior.
We recommend against using the more complex Redux-Saga and Redux-Observable libraries in most cases, especially for async data fetching. Only use these libraries if no other tool is powerful enough to handle your use case.
Move Complex Logic Outside Components
We have traditionally suggested keeping as much logic as possible outside components. That was partly due to encouraging the "container/presentational" pattern, where many components simply accept data as props and display UI accordingly, but also because dealing with async logic in class component lifecycle methods can become difficult to maintain.
We still encourage moving complex synchronous or async logic outside components, usually into thunks. This is especially true if the logic needs to read from the store state.
However, the use of React hooks does make it somewhat easier to manage logic like data fetching directly inside a component, and this may replace the need for thunks in some cases.
Use Selector Functions to Read from Store State
"Selector functions" are a powerful tool for encapsulating reading values from the Redux store state and deriving further data from those values. In addition, libraries like Reselect enable creating memoized selector functions that only recalculate results when the inputs have changed, which is an important aspect of optimizing performance.
We strongly recommend using memoized selector functions for reading store state whenever possible, and recommend creating those selectors with Reselect.
However, don't feel that you must write selector functions for every field in your state. Find a reasonable balance for granularity, based on how often fields are accessed and updated, and how much actual benefit the selectors are providing in your application.
Name Selector Functions as selectThing
We recommend prefixing selector function names with the word select, combined with a description of the value being selected. Examples of this would be selectTodos, selectVisibleTodos, and selectTodoById.
Avoid Putting Form State In Redux
Most form state shouldn't go in Redux. In most use cases, the data is not truly global, is not being cached, and is not being used by multiple components at once. In addition, connecting forms to Redux often involves dispatching actions on every single change event, which causes performance overhead and provides no real benefit. (You probably don't need to time-travel backwards one character from name: "Mark" to name: "Mar".)
Even if the data ultimately ends up in Redux, prefer keeping the form edits themselves in local component state, and only dispatching an action to update the Redux store once the user has completed the form.
There are use cases when keeping form state in Redux does actually make sense, such as WYSIWYG live previews of edited item attributes. But, in most cases, this isn't necessary.